By Suhani Singh
The previous three blogs in this four-part series have explored the voting intentions of Ontarians during the 2018 general election. The voting trends observed overall, in each gender, and each age group were discussed in the previous blogs. This blog examines regional voting preferences noting trends and differences. Polling data was categorized based of the common regional breakdowns including:
- Toronto 416
- Greater Toronto Area 905
- Eastern Ontario
- South Central Ontario
- Southwestern Ontario
- Northern Ontario
In order to determine the number of seats won by each party in a given region, the winners from each riding were added up based on CBC tracker results.
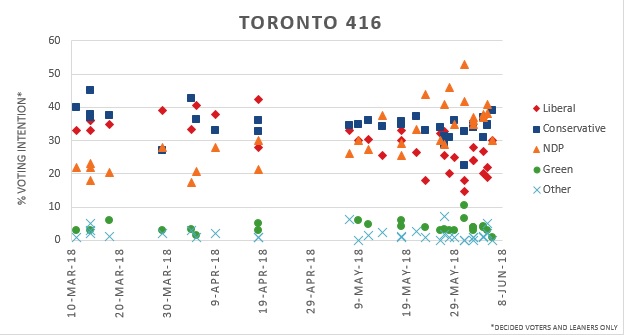
The Toronto 416 region represents the city core and close surrounding areas. The Conservatives polled between 35% – 45% during the pre-campaign period closely followed by the Liberals (30% – 40%) while the NDP remains low at around 20%. NDP support rose to 25-45% support during the campaign leading the Conservatives and NDP to be in a close race. Liberal party support significantly decreases over time falling between 15% – 30% before the election. This was a dramatic drop since the Liberals were polling similar to the Conservatives in the pre-campaign period.
In the 416 region, the PC and NDP tied winning in 11 seats each and the Liberal party claimed 3 seats.
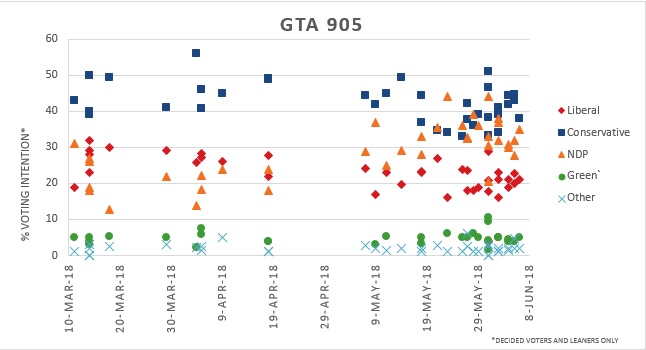
In the Greater Toronto Area 905 region, The Conservatives polled rather high (between 40% – 50%) during the pre-campaign period followed by the Liberals (at 20% – 30%) and the NDP (15%-25%). The NDP rose significantly during the campaign period to 25%-40% resulting in a close Conservatives and NDP race. Liberal support decreases over time dropping to 15% – 25% close to the election.
Though the polls show that the NDP gained significant support in the month of May, the Conservatives won a landslide in the 905 area taking 31 seats. The NDP won only 4 seats and the Liberals failed to win any seats despite consistent levels of support. These results reveal how the Ontario first-past-the post-election system can obscure significant support for parties in some areas.
In Eastern Ontario, Liberal support stayed stable between 20% – 30% support throughout the pre-campaign and campaign period. NDP support rose slightly from 15%-25% during the precampaign period to 20% – 35% closer to the election. The Conservatives remained on top throughout despite a falling from 40%-55% to 30-50% as the election approached.
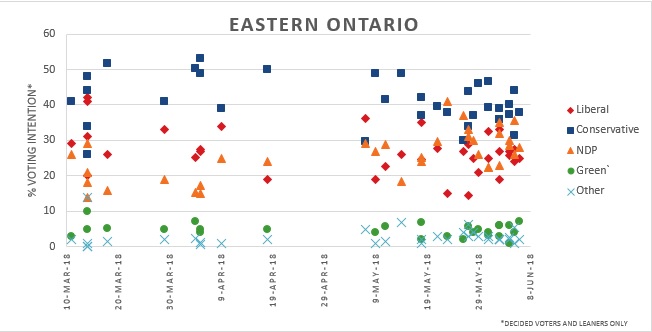
The Conservatives emerged as the winners of 14 seats, while the NDP won 2 and Liberals won 3.
In South Central Ontario, Conservative support had a slight fall over time but largely stayed on top of the other parties polling between 30 – 50% near the election. The NDP saw a significant growth in their supporters, starting from the 20% range and rising up to 30% – 55% toward the end.
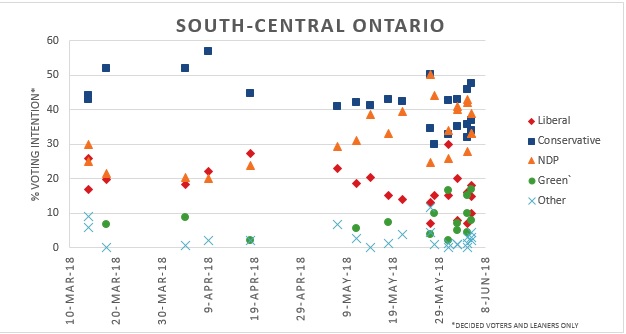
Polls indicated a tight race between The Conservatives and NDP as the election approached with the NDP eventually claiming victory in the region winning 7 seats while the Conservatives gained 4. Liberals saw a drop in their support (5% – 20%) over time polling similar to the Green Party and falling below the national average (15%-25). Neither party won any seats.
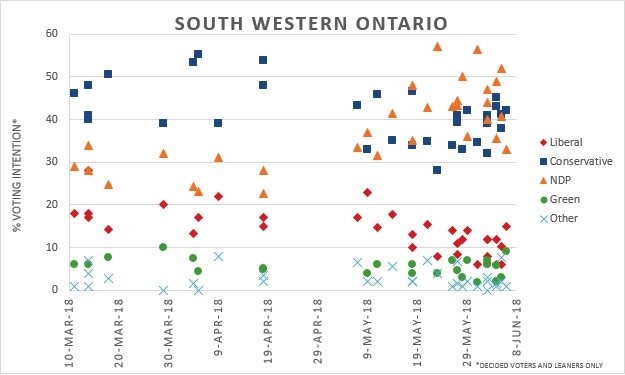
In South-western Ontario, Conservatives polling between 40% to 55% during the precampaign period but saw a drop to 30% – 45% closer to elections. The NDP went from 30% at the start to 40% – 55% closer to elections making it a close race between the two parties. Liberal support was low (15%-20%) to begin with and saw further drop to 5% – 15% over time. Green Party support was somewhat low (<10%) and stable in this region but the party saw won its first seat in Guelph. Liberals failed to win any. PCs won 12 and the NDP finished with 8.
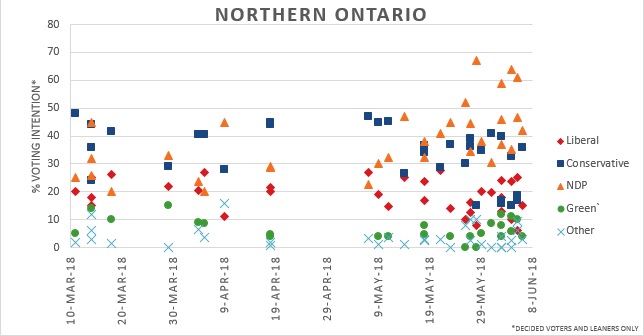
Conservatives and the NDP start polling similarly in Northern Ontario between 20% – 50% but the PCs saw a decline to 15% – 40% in late May while the NDP polled 30% – 60%. It should be noted the support range for individual parties was very large, likely due to this region having the smallest sample sizes. However, polls were relatively reflective of the results which saw the NDP win 8 seats and the PCs 4 seats. The Liberal Party saw some decline from 20% – 25% in precampaign period to 5% – 25% near the election They managed to win 1 seat in this region.
Overall, the PCs won 76 seats, NDP won 40, and the Green Party one 1. Liberals managed to win only 7 seats, one seat shy of maintaining their official party status. This Ontario 2018 elections blog series, looked at the different trends in voting intentions among Ontarians. Men and women presented difference in their choice of preferred party. Party choice also varied from region to region and from generation to generation.