The Dyad Ratio Algorithm, as explained in the previous post, can be used to estimate public opinion towards issues or support for political parties. This approach does not weight the polling firms on their accuracy or their potential bias instead all surveys are assumed to be equally valid, with the only variance in importance of a poll for the model based on the survey sample size. This is contrast to Éric Grenier’s approach at CBC and Nate Silver’s approach at fivethirtyeight.com.
Grenier at CBC weights the results by sample size, time of the poll, and firm accuracy. Polling firm accuracy is determined by the firm’s last survey before an election compared to the election result for each election polled over the past ten years. A survey’s impact diminishes by 35% for each day of an election. Silver at fivethirtyeight.com also uses accuracy of the polling firm and a measure for house effects which is built into the model itself. Silve’s approach also uses sample size to weight the impact.
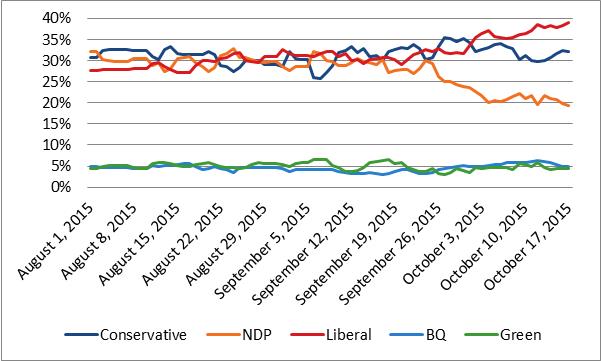
ThreeHundredThirtyEight.com at this time does not have a record of the accuracy of polling firms, as such the approach used here accounts for each poll equally in the results. When examining the 2015 federal election the model’s approach performed quite well at predicting party support.
Comparing the projections from the Dyad Ratio Algorithm using Wcalc to the election results each outcome is within 1.1 percentages points of the final results. (Note the election results were re-calculated to remove those who voted for an ‘other’ party). The Conservatives are projected exactly, Bloc within 0.2 percentage points, the NDP are within 0.5 percentage points, the Liberals within 0.8 percentage points and the Greens within 1.1 percentage points.

The results of the Dyad Ratio Algorithm also outperformed the projection from Éric Grenier narrowly. Grenier has the Conservatives within 1 percentage point, Bloc within 0.2 percentage points, the NDP are within 2 percentage points, the Liberals within 2.3 percentage points and the Greens within 1 percentage point. Though it is worth noting that Grenier’s projections were able to include ‘other’, which he projected to yield 0.9% support compared to the 0.8% they actually received. Also, in fairness, the Dyad Ratio Algorithm projections are being made after the fact and Grenier’s were made in real time before the election results were known. To put it another way, if these results had shown ThreeHundredThirtyEight.com to do significantly worse this model would have been re-examined.
The next step is to begin testing the model to predict support during elections. Future posts will use data from Wikipedia to show how the Dyad Ratio Algorithm is projecting support for the federal parties on an on-going basis.